At least from the other simulations (though much shorter) the volatility didn’t change much for ordinary players, so if there is a math mistake or rounding error, it might only be happening for volatile play ![]()
If it was doing what it is supposed to, I would expect it to take fewer than 1000 games to settle on the correct (possibly high) volatility. Is it even approaching a limiting value? What if the initial volatility is set higher or lower than .06? What if you run similarly long simulations for the other players?
Well we know it’s going to be forcefully capped by the maximum set in the code. Then again it’s not like the player is stopping being volatile - in that example the player is jumping from “playing” as a 5kyu or a 15kyu based on a coin toss.
Well that also assumes we know what it’s supposed to do. What if it currently is doing what it’s supposed to do it’s just we don’t like that it’s doing that for reason X?
We could test for instance what happens if two ordinary players at the same rating and deviation play with expected results but one has 0.06 volatility and the other has a high value like 0.1, and then track how or if the volatility settles based on the results.
I could do that, but the thing is if you just look at every “normal” OGS player, you know that you don’t get a runaway linearly increasing volatility just by observation. They seem to stay around this 0.06 value.
Overall I’d have to read the glicko papers in detail (and I might need a bit of help or more background, or maybe LLMs can help these days) to see where this number comes from, if it or some nearby value is like a stable/fixed point of the algorithm or something like that.
The point I was making to @Jon_Ko was that volatility is not just about the level you play at (or so it seems), it’s about the opponents level also.
You don’t see the volatility rise linearly when the opponents are the same rank as the player was at initially.
The example case shown here was when you have the chance to behave in a “volatile” way, where you play a wide range of opponents, and you lose disproportionally often to lower rated opponents than your current rank, that it seemed to increase the volatility linearly.
If you have suggestions as to what is worth spending time trying to simulate, I’m interested in doing it. Like if you have some idea in particular to challenge: volatility should increase when X behaves like this or in situation Y; or I expect that volatility should settle at this high value A for reason B.
Or if you have any ideas where you think there might be an issue in the implementation or the glicko2 algorithm itself.
Am I implying that there’s no typos in the code or algorithm? No definitely not. There was a previous issue in the volatility and that was eventually corrected for example.
There was an example of players rating graphs before and after the change given
1 Like
How many normal players have 10k+ completed games? Also, the increase was very small, from .06 to .064, so it might not be noticeable anyway? I was thinking this might be a problem for popular bots with hundreds of thousands of completed games.
The main theory I want to test: Any player with a sufficiently high proportion of unexpected results will achieve unbounded volatility.
The simulations I would suggest (all against random stable opponents):
Stable 5k.
Weak sdk. 50% win probability against any player 5k-10k, normal win probability against anyone else.
Bot: 50-50 15k and 5k
Sandbagger: win probability against x kyu is as if sandbagger is a 7k playing a (15-x) kyu (wins more against stronger opponents)
For each of these players, start at .06, .1, and .14 volatility. Run for 10k games. This will hopefully show if the slope is decreasing, so we can detect an approach to some limiting value.
I would expect a reasonable rating system to have some finite limiting volatility for the first three of these players, increasing from top to bottom. (glicko2 seems unreasonable in that one chart, but we may have just gotten lucky and .06 is close to the limiting volatility for that player?)
These sound very volatile. A weak sdk probably won’t have a flat 50% win chance against such a high range of opponents. We do need a true rank though so we have a meaning to “normal win probability against anyone else”. So pick them as like 5k also?
The bot is the one we have for comparison, but we can see what happens at different starting volatilities.
I don’t expect the volatility to stabilise but I also didn’t expect some of the ways the deviation changed before so we’ll see ![]()
I don’t really understand this. You’re saying a 7kyu can beat a 3kyu like they’re a 12kyu, a 2kyu like 13kyu, a 1kyu like a 14kyu?
That’s a strange trend that they play stronger vs stronger players beating them even more definitively the stronger they get.
A simpler model of a sandbaggers might be resigning against weak players a certain maybe high percentage of the time while winning against strong players a normal amount of the time given a fixed level. Assume the sandbaggers is 2d but they pair up and lose against some ddks when their rank gets too close to 2d and they play like a 2d otherwise.
It’s a bit drastic but if you want it to be effective you beat slightly easier than your true rank opponents, while throwing games against much lower ranks to lower your rating quicker.
I didn’t pick 10k because it was realistic for a normal player, I picked it to see a long term trend for what’s happening with the volatile site bots. Cut that off at 1k or 2k games and it’s the same trend. It’s still going upward and you know it will continue upward for a while.
I don’t really expect a reasonable rating system to assume that players are permanently volatile and try to model for that.
Most rating systems assume the game is more about skill than luck, and that players can have a reasonably accurate rating assigned to them that measures their skill.
Elo and glicko I don’t think have an assumption built in that says half the time you might just resign some of your games to sandbag and that’s accounted for in the win probability.
If you had a rating system for card games or other board games which have a higher luck to skill ratio instead, maybe they’d be better at modelling the randomness that comes from regular unexpected outcomes from bad shuffles or bad dice rolls etc.
1 Like
Yes. I was not intending to realistically model a sandbagger, but rather find an extremely-high-volatility player.
I probably should have said this earlier - I hypothesize that volatility is correlated with rank being less predictive of outcome, in the sense of the winrate vs rank curve having higher (less negative) slope. It would be cool to see winrate vs rank curves for the simulated players (as well as a population vs rank curves). I would be interested in making one for the ogs bots to compare.
A slightly-volatile player has less extreme winrates than expected - imagine someone who is a “true” 5k but randomly resigns 1% of games. They will settle at 5.x kyu, but will do better against stronger players and worse against weaker players than expected. (consider the graph of rank vs. winrate against this player. afaik glicko is translation-invariant, so the slope at equal rating should be the same regardless of rating, but the slope for this 5.x kyu is 99% that of a 5 kyu.) Your “bot” is very volatile: the winrate curve will be almost flat over much of the 5k-15k range. I intended my “weak sdk” to be a bit less volatile than that, but the flat region of the graph should probably be narrowed (maybe 4-6k, true rank 5k. No longer so weak lol). You might think the maximally volatile player always has 50% winrate - the outcome is entirely luck regardless of rank, and winrate curve is flat everywhere - but you can actually go even more volatile than this by having winrate increase with rating.
I think it has to do this - players sometimes time out in a way that is uncorrelated with opponent skill, and sometimes resign because they have to e.g. catch the bus. I think 1% permanent random resignation probability is realistic for human players.
2 Likes
Ah ok, then yes something like the 7k with treat opponent x as 15-x makes sense to me, it’s like flipping the expected results ![]()
Well supposedly there is a function that I was using to approximate the winrate, I just haven’t adjusted it from glicko to glicko2, and some comments in the caveats bit.
Well if two players are perfectly equally rated in theory (skill), then we do expect the results to be like a series of coin flips and the ratings are bit like a random walk. I think that does mimic the idea of volatile in a way (visually), because the ratings of the players don’t really settle down (at least I don’t think they do) relative to each other. But I don’t think the volatility skyrockets in this case, it’s kind of within some expected set of outcomes in a way.
Yeah your second example player should be interesting for that one.
And I don’t think any reasonable rating system should factor this in either. I don’t think when Arpad Elo sat down to try and fix the Chess ratings issues they were having, he said “and I better allow a 1% chance that a player might need to go for a bus” or that “this skill assumption only makes sense with 4hours main time and an increment of 30s per move”.
All these sorts of factors are additional things you can patch onto a rating system (which is only an approximation of skill at a game) to try to limit results to actual useful data if you want.
The EGF gives a fraction of the points when the settings are too fast or when it’s online. I would assume it’s because those results are less predictive of skill than longer time games (within reason) because of random chance factors, and also because at some point playing the clock instead of the game is part of the strategy.
Bullet chess is an example where playing well with the clock is probably more important than playing chess well, although at the increasingly higher levels you have to do both sufficiently well. A coin flip might become a good approximation though as to who will win for a large range of ratings, as maybe the person that warmed up their pre move skills will win on time or the person who had a more recent cup of coffee for the slightly faster reaction speed.
1 Like
I didn’t come back to this yet, but I plan to with a bit more time.
Still interesting enough would be to track some of the new bots like Oroton
https://online-go.com/termination-api/player/1893795/v5-rating-history
It’s played maybe a couple of hundred ranked games and the volatility is still around 0.06.
And another bit more recently added
https://online-go.com/termination-api/player/1904320/v5-rating-history
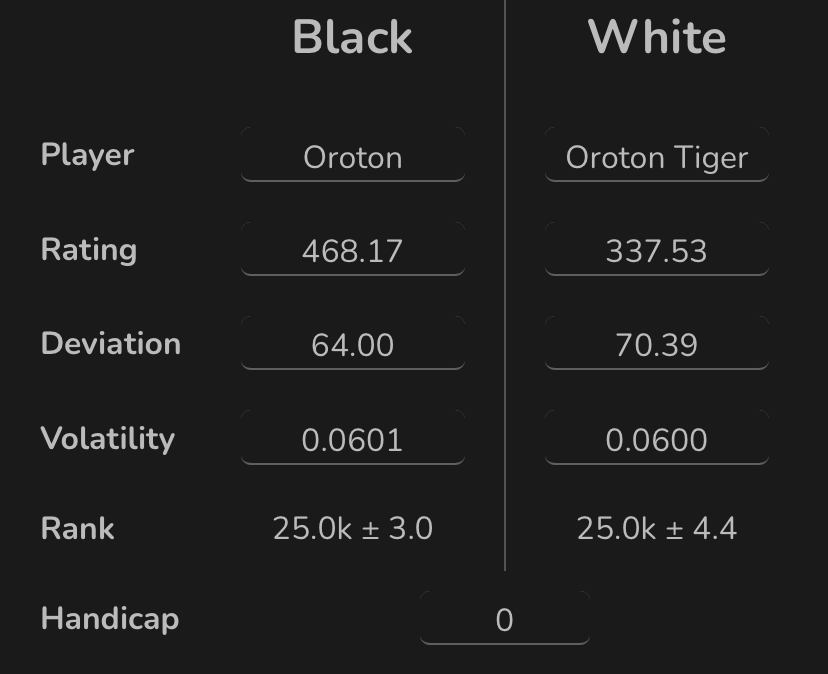
So it could be interesting to see if and when the volatility of these bots increases or not.
See more here
2 Likes
Randomly brought back here again.
I don’t think the Oroton bots play that many ranked games, maybe still less than 2500 for Oroton and less than 1500 for tiger (at a rough glance) in the last few months, and the volatilities have gone from 0.06 to 0.06069 ish and for tiger to 0.0605 ish.
It seems like quite a slow crawl upward.
1 Like
I ran into the second person that lost a bunch of games against KingGator-bot. They play legit games, so it’s technically not sandbagging, but their rank ropped massively within 20 or so games.The players should be in my rating range. The bot is currently rated 3k, while the profile says it’s rating should be 2-5d. The highest I have seen was 7d.
The results of the bot are all over the place, idk. Sometimes he demolishes dan player, then he loses against 17k.