Google finally came forward with the “major” announcement about their ground breaking go AI. Huge news!
It has made some big discussions on English channel and also on other places(forums, servers, irc, etc.)
I just prefer OGS forum platform over all else 
Feel free to hijack this thread.
6 Likes
OGS overlords! Will there be any possibility of getting coverage of AlphaGo’s game against Lee Sedol?
1 Like
My mind is just totally blown away. THIS IS NUTS. I’ve been following developments on this matter, reading recent papers on deep learning go, but this result is just beyond impossible. One of the most groundbreaking achievements in the history of AI and computing.
1 Like
personally i’m pretty disappointed:
-
i was hoping that go would present an interesting computing challenge for far longer
-
that neural nets, which are essentially a black box with a bunch of tuned weights, generates
a bunch of suggestions that are fed into the standard monte carlo machine. so it seems
like we didn’t learn a lot
however, the fact that after bootstrapping the system sufficiently, setting it against itself letting it
learn in corner, it got better. on its own. thats kind of outweighs my biases towards discredited
logical frameworks.
2 Likes
BTW, full paper here: https://storage.googleapis.com/deepmind-data/assets/papers/deepmind-mastering-go.pdf
Absolutely fascinating read.
Also, can’t wait to see the match against Lee Sedol in March! This game may be even more historically significant than DeepBlue vs Kasparov.
4 Likes
has the game records inlined.
that was not a marginal victory
3 Likes
Yeah, that’s more of advance in AI research than in go research. The answers that kind of AI gives are in vein of “this move is better because it is”. I guess the next challenge will be to create an AI capable of writing go theory books ![]()
Still, exciting news.
4 Likes
Uploaded SGFs to OGS:
8 Likes
Nice review of the first game: http://gooften.net/2016/01/28/the-future-is-here-a-professional-level-go-ai/
5 Likes
A review of game 5
4 Likes
While the techniques Google used are interesting (mixing suggestions from a neural network with Monte-Carlo Tree Search, and using reinforcement learning), I am not sure that the leap in strength is so revolutionary.
Plus, it looks to me like they exaggerate the progress made in the diagram of their article where they put amateur 7, 8 and 9 dans below the strength of their programs: I don’t recall that there is really any amateur at these levels, so it looks to me like they are blowing up the scale so as to show a strength improvement better than it really is.
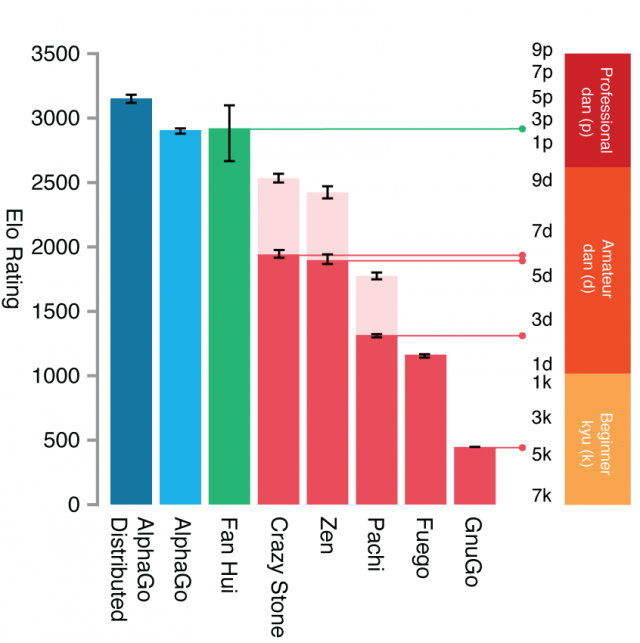{kind=link}
The strength of Crazy Stone at about 6d (amateur), and AlphaGo’s at 2p+ thus do not look (to me) too far from each other. Especially compared to the huge jump in strength that Monte-Carlo Tree Search brought.
On the other hand, they do put an ELO scale in their paper: do you guys have an opinion of how relevant that scale is compared to the kyu/dan levels they use? how big is the jump in strength compared to the jump obtained with Monte-Carlo Tree Search a few years ago?
In any case, it is possible that AlphaGo hasn’t yet shown its full strength, as Monte-Carlo Tree Search programs tend to just do enough to win instead of trying to win by a large margin.
For that particular diagram, I think the primary thing to consider is the Elo scale on the left. They even say that the kyu/dan ranks that they put on the right are just an approximation, as anyways kyu/dan ranks are somewhat imprecisely defined. The Elo rankings are estimated based on an internal tournament among the various AIs, which seems like a reasonable way to approximate these.
As for whether the jump in strength is “revolutionary”, I guess that’s a more subjective question. That diagram isn’t the point, the main point is that this AI is the first to have beaten a pro-level player (however, granted, a lower ranked one) in not only one even game, but in every game of a series of 5. Interestingly, however, AlphaGo only won 3 out 5 “informal” games played with Fan Hui with much shorter time controls.
I think it’s justified calling AlpaGo revolutionary and a big leap, since prior programs have required 3-4 stones to play competitively against top players, and especially since many felt that we were still at least a decade from reaching this stage.
3 Likes
DeepMind used existing techniques in combination with the extraordinary result we are now discussing. They know that they are standing on the shoulders of those that came before.
There are few aspects of this that I think make this a huge accomplishment:
- This program represents a significant jump in strength relative to the strongest programs previously available
- This program doesn’t play in an obviously artificial manner
- This program plays with a recognizable style (The reviewer last night said it played with a Japanese style)
Only time will tell if there is a completely new technique in here that could be considered revolutionary. However, DeepMind has succeeded in advancing each of the methods more than before and then combining them in a manner that results in a further advance in the outcome.
Finally, if anything, I think their presentation may understate the advance relative to human players. I think they were trying to fill in the gap. To some extent, this the quantum leap between amateurs and pros. Even lower level pros see the game differently than the rest of us. The best of them might as well come from a different planet.
I can’t wait for the games in March. At worst, I think we will see some great Go.
4 Likes
Very interesting information, yebellz, about the ELO scale.
Now, I also remember that “prior programs have required 3–4 stones to play competitively against top players”, but I also remember (incorrectly??) that the gap between 1p and 9p is about 3 stones, so my guesstimate was that completely beating a 2p was clearly better than beating a 9p with 3-4 stones, but not by too much (since 9p - 3 stones ~ 1p/6d). The ELO scale tells a different story, though, and I follow you in saying that AlphaGo’s level jump is big.
Now, if anybody can make the story work in the dan (amateur and pro) realm, that’d be illuminating.  To summarize: the previous best programs where 6d amateur; I understand that the next level is about 1p, which is consistent with the idea that the best programs need 3–4 stones to beat a 9p (assuming 3 stones between 1p and 9p), and which points to the idea that beating a 2p is not such a big jump in strength (which, says the ELO scale in the AlphaGo article, is an incorrect conclusion).
To summarize: the previous best programs where 6d amateur; I understand that the next level is about 1p, which is consistent with the idea that the best programs need 3–4 stones to beat a 9p (assuming 3 stones between 1p and 9p), and which points to the idea that beating a 2p is not such a big jump in strength (which, says the ELO scale in the AlphaGo article, is an incorrect conclusion).
Dan/kyu ranks in general are a bit arbitrary and sometimes imprecise. First, there is no absolute notion of a 6-dan amateur, since ranks vary significantly between servers/organizations.
Behinds the scenes of many of these amateur ranking systems is usually an Elo-like system. This Elo score is then quantized to dan/kyu levels. However, for professionals, the ranks are based various promotion guidelines, and the ranks are never adjusted back down (i.e., a pro that reaches 9p remains 9p for the rest of his life, even if his skill declines as he ages).
I’ve heard of that rule of thumb that 1p vs 9p is roughly 3 stones, however, I’ve also heard that in recent times, the pro ranks are a significantly closer (maybe 2 or less stones between 1p and 9p).
Several servers/organizations do use amateur ranks above 6 dan (see the worldwide rank comparison posted above). In fact, if you read the paper, you will see that they mention training their AI based on games of amateur 6 through 9 dans on KGS. It seems that the dan strengths that they mentioned are based on the KGS ranks.
https://storage.googleapis.com/deepmind-data/assets/papers/deepmind-mastering-go.pdf
1 Like
It would be really interesting to know more about the training process. The paper only mentions the KGS data set (apart from reinforcement learning).
I couldn’t help but laugh when I read that. No offense to KGS high dans, but aren’t they mostly blitzing while drunk? Not to mention that even the strongest amateurs are not quite as strong as most professionals.
Surely they must have used some pro game collections as well. They just don’t mention it.
Two guys at Facebook has also demonstrated some progress: arxiv.org/abs/1511.06410 They not only made some claims, but also proved them by releasing a bot on KGS that maintain 5d. Their paper also contains more technical details about how their bot works.
Here are some comments on how big the improvement in level is compared to what Monte-Carlo Tree Search brought (all cited levels are only approximations—they depend partially on the rank scale used, etc.).
Before MCTS (2006), I understand that the level of programs was maybe about 10 kyu: Gnu Go was 2006 Computer Olympiad champion, and 10 kyu was about his level at the time. MCTS quickly made the level jump to about 2 kyu, with strengths that now reach about 6 dan amateur. According to Google’s strength graph in their paper, MCTS thus allowed computers to gain about 1000 ELO initially and about 2000 ELO in 10 years.
This appears comparable to the initial improvement of AlphaGo (about 1000 ELO). Which makes it an impressive result in terms of strength increase, indeed.
2 Likes
They use the KGS data to train one network (predict next move, called SL in the paper). They then use that network to seed a reinforcement learning (RL) network, which plays against itself (and past versions of itself) to improve. That network is then used to train the Value network (used for position evaluation).
As I understand it, the final result is a MCTS using the SL+Value networks to choose where to explore. SL+Value was better than RL+Value. Note that their Value network alone (no MCTS) would in the mid-dan range, already.
2 Likes
I have never wanted to play a robot until now. In fact, I still do not want to play against robots.
I think AlphaGo functions as Sai… A ghost in the machine.
I definitely want to play, lose and learn against it.
2 Likes